
Study Highlights Why OTFS Outperforms OFDM in Doubly-Dispersive Channels
4 Dec 2025
OTFS delivers major spectral-efficiency gains over OFDM through reduced training overhead, improved channel modeling, and accurate D-D domain prediction.
Numerical Tests Highlight OTFS’s Spectral-Efficiency Gains Over OFDM
4 Dec 2025
OTFS shows higher robustness and spectral efficiency than OFDM in high-mobility channels, as simulations highlight severe ICI and estimation limits in OFDM.

Why OTFS Outperforms OFDM in High-Mobility Scenarios
4 Dec 2025
Explores how OTFS uses D-D domain predictability to interpolate, extrapolate, and track wireless channels, reducing pilot overhead in high-mobility scenarios.
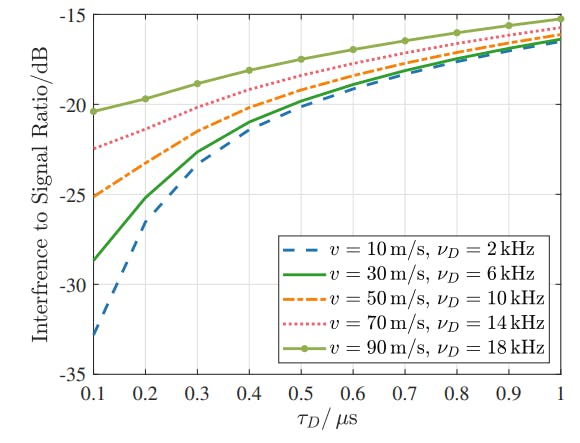
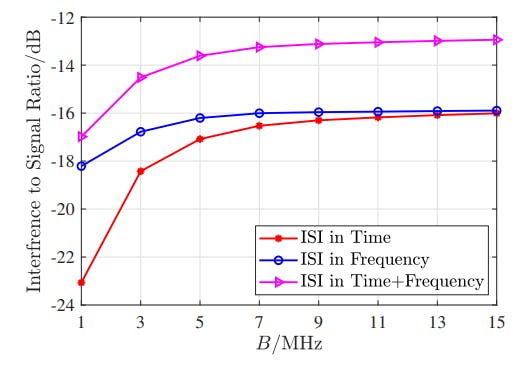
Researchers Explain How Delay–Doppler Spread Affects Interference in Discrete Channel Models
3 Dec 2025
A technical breakdown of channel discretization, showing how sampling, pulse design, delay, & Doppler spread shape ISI, ICI, and overall TF-domain interference.
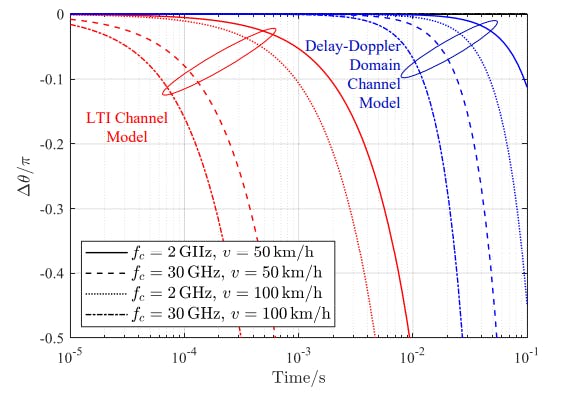
Why First-Order Channel Models Matter for High-Mobility Wireless Systems
3 Dec 2025
A clear explanation of why OFDM’s LTI models fail in fast-changing channels and how first-order and delay–Doppler models improve accuracy and performance.
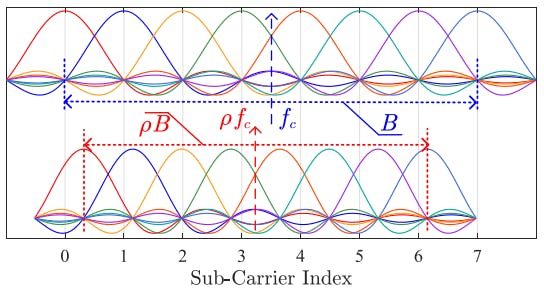
Study Connects Doppler-Domain Sparsity to OTFS Performance Edge
3 Dec 2025
Technical analysis showing why OTFS is essential for dynamic wireless channels, offering major spectral efficiency and channel estimation advantages over OFDM

Study Finds OTFS Can Dramatically Cut Channel Training Costs in High-Mobility Networks
3 Dec 2025
OTFS significantly reduces channel training overhead in doubly-dispersive channels, outperforming OFDM as Doppler and delay effects increase.
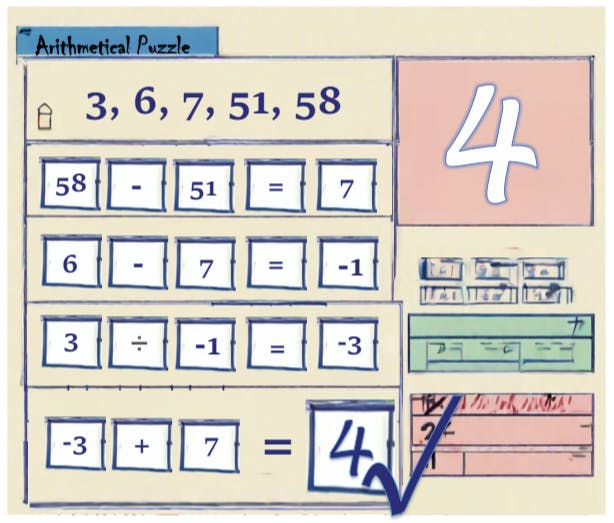
Why LLMs Struggle with Arithmetic Puzzles
23 Aug 2025
We tested GPT-4, Llama-2, and more on symbolic puzzles—see why even the strongest LLMs fail without fine-tuning.

Testing Large Language Models on Math Puzzles
23 Aug 2025
Can LLMs solve math? This study explores puzzles, synthetic data, and fine-tuning to push AI’s limits in reasoning and extrapolation.